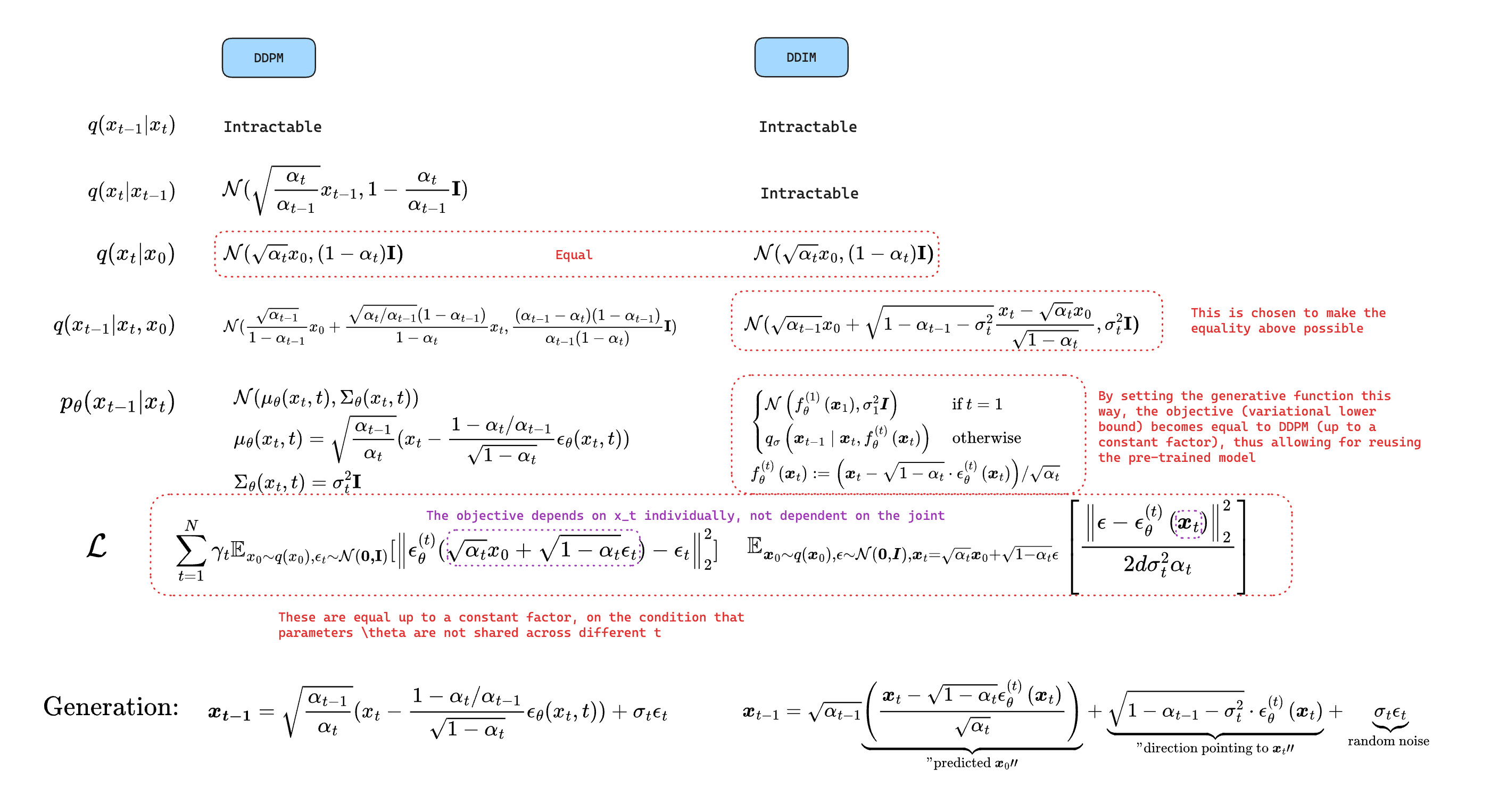
I’m a visual learner, so it’s easier for me to learn a concept if they are visually structured in a meaningful way. Here’s my attempt with “Denoising Diffusion Implicit Models”, an influential paper that came out in ICLR 2021.
Takeaways
- DDIM actually has 2 contributions
- A variance hyper-parameter schedule $\sigma_t$ is introduced to increase the flexibility of the inference process.
- when $\sigma_t = 0$, it’s deterministic/implicit
- when $\sigma_t = \sqrt{\frac{1 -\alpha_{t-1}}{1 - \alpha_t}(1 - \frac{\alpha_t}{\alpha_{t-1}})}$, it’s equivalent to DDPM
- Realized that the variational objective doesn’t depend on the joint distribution $p_\theta(x_{1:T}|x_0)$, but rather on the marginals $p_\theta(x_t|x_0)$ “independently”. This allows for a re-formulation of the inference and generation process to a non-markov process, while keeping the training process/objective unchanged (same model!)
- A variance hyper-parameter schedule $\sigma_t$ is introduced to increase the flexibility of the inference process.
- These 2 contributions are independent, in that the reformulation can be applied directly to DDPM without introducing the variance schedule.
Cheatsheet